# 面经手册 · 第5篇《看图说话,讲解2-3平衡树「红黑树的前身」》
作者:小傅哥
博客:https://bugstack.cn (opens new window)
沉淀、分享、成长,让自己和他人都能有所收获!😄
# 一、前言
讲道理5年开发,没用过数据结构,你只是在做CRUD!
很多时候大部分程序员👨💻头疼于,查询慢、效率低、一堆的关联SQL,主要原因是在程序设计上没有做出很好的数据结构。当然也还有一部分是由于老业务代码,或者没有用到一些大数据服务等。
数据结构、算法、设计模式,是每一个程序员成长过程中的内功心法修炼,而你的新技能用的再绚、多线程使的再6、加锁玩的再牛🐂,也只能说明你这个人身体好,但身体好是不能抗住子弹的。只有身体+心法都好,都能纵横捭阖。
这一章节是结合HashMap的延展,在Jdk1.8中HashMap是使用桶数组+链表和红黑树实现,所以顺着上一章节的核心原理和API功能讲解后,本来这一章节想直接进入到红黑树,但如果想把红黑树学明白,就需要了解他的来龙去脉,也就是它的前身2-3树🌲。
# 二、面试题
谢飞机,考你几个简单的知识点🦀
- 飞机,看你简历写了解数据结构,可以简单介绍下2-3树吗?
- 这种树节点有什么特点,与你了解其他的树结构对比下?
- 你看这个图,向里面插入和删除节点,要怎么操作?
🤥飞机,回去等消息吧!
# 三、什么是2-3树
日常的学习和一部分伙伴的面试中,竟然会听👂到的是;从HashMap中文红黑树、从数据库索引为B+Tree,但问2-3树的情况就不是很多了。
# 1. 为什么使用树结构
从最根本的原因来看,使用树结构就是为了提升整体的效率;插入、删除、查找(索引),尤其是索引操作。因为相比于链表,一个平衡树的索引时间复杂度是O(logn),而链表的索引时间复杂度是O(n)。
从以下的图上可以对比,两者的索引耗时情况;
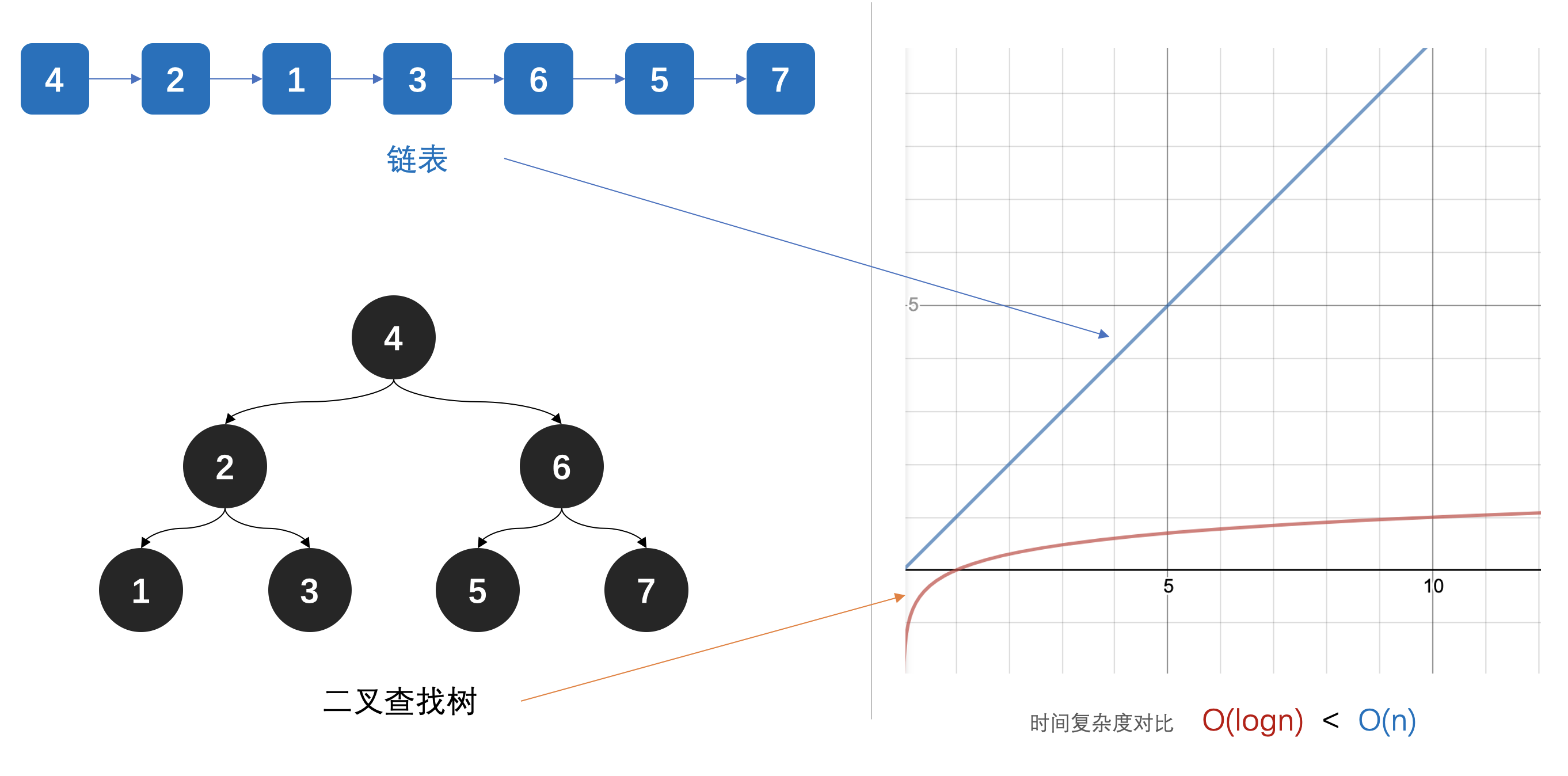
- 从上图可以看到,使用树结构有效的降低时间复杂度,提升数据索引效率。
- 另外这个标准的树结构,是二叉搜索树(Binary Search Tree)。除此之外树形结构还有;AVL树、红黑树、2-3树等
# 2. 二叉搜索树退化链表
在树的数据结构中,最先有点是二叉查找树,也就是英文缩写BST树。在使用数据插入的过程中,理想情况下它是一个平衡的二叉树,但实际上可能会出现二叉树都一边倒,让二叉树像列表一样的数据结构。从而树形结构的时间复杂度也从O(logn)升级到O(n),如下图;

- 二叉搜索树的数据插入过程是,插入节点与当前树节点做比对,小于在左,大于在右。
- 随着数据的插入顺序不同,就会出现完全不同的数据结构。可能是一棵平衡二叉树,也极有可能退化成链表的树。
- 当树结构退化成链表以后,整个树索引的性能也跟着退化成链表。
综上呢,如果我们希望在插入数据后又保持树的特点,O(logn)的索引性能,那么就需要在插入时进行节点的调整
# 3. 2-3树解决平衡问题
2-3树是什么结构,它怎么解决平衡问题的。带着问题我们继续🤔。
2-3树是一种非常巧妙的结构,在保持树结构的基础上,它允许在一个节点中可以有两个元素,等元素数量等于3个时候再进行调整。通过这种方式呢,来保证整个二叉搜索树的平衡性。
这样说可能还没有感觉,来看下图;
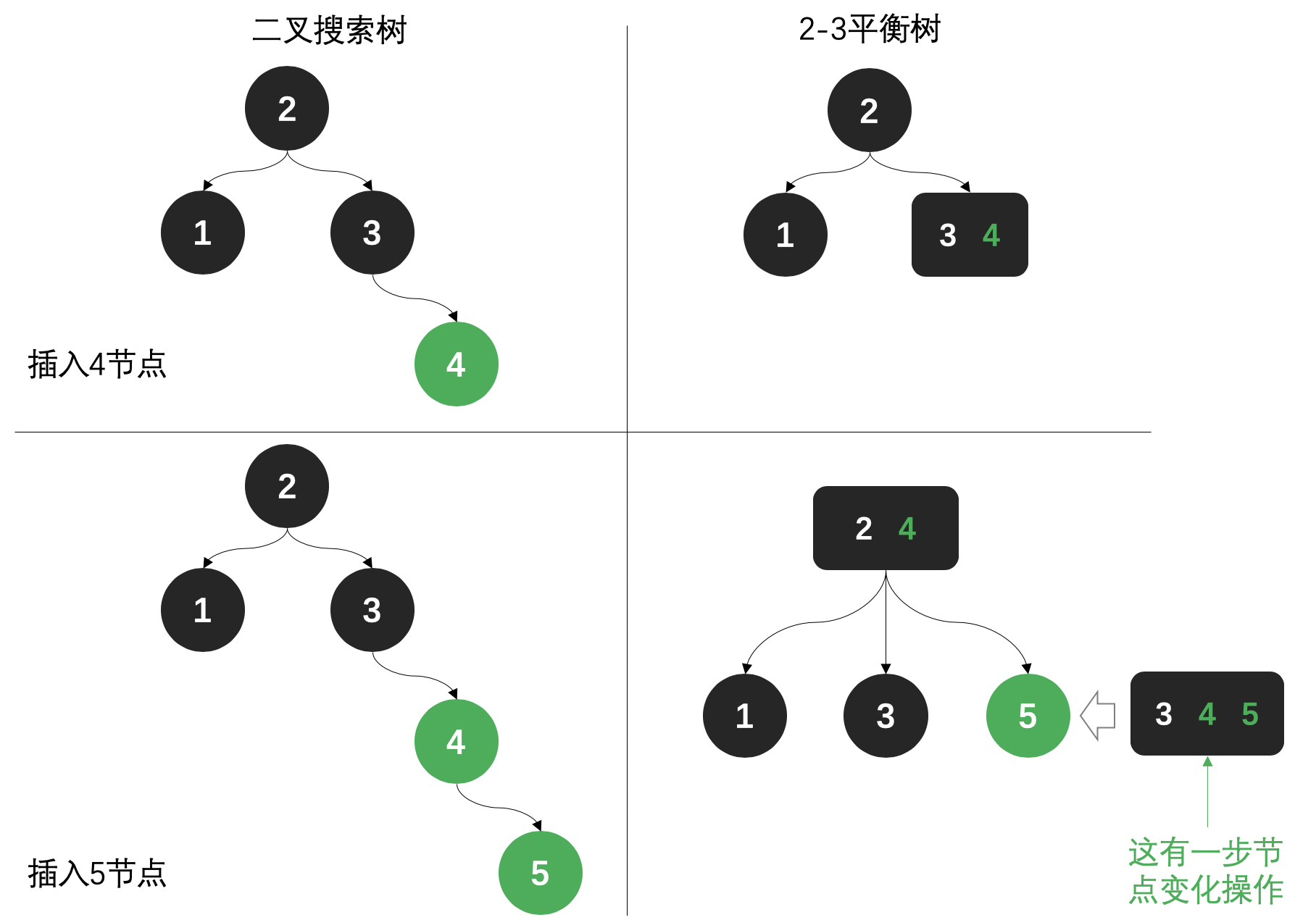
- 左侧是二叉搜索树,右侧是2-3平衡树,分别插入节点4、5,观察树形结构变化。
- 二叉搜索树开始出现偏移,节点一遍倒。
- 2-3树通过一个节点中存放2到3个元素,来调整树形结构,保持平衡。所谓的保持平衡就是从根节点,到每一个最底部的自己点,链路长度一致。
2-3树已经可以解决平衡问题那么,数据是怎么存放和调整的呢,接下来我们开始分析。
# 四、2-3树使用
# 1. 树结构定义和特点性质
2-3树,读法;二三树,特性如下;
| 序号 | 描述 | 示意图 |
|---|---|---|
| 1 | 2-,1个数据节点2个树杈 |  |
| 2 | 3-,2个数据节点3个树杈 | 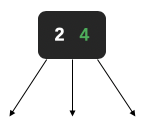 |
| 3 | 三叉与两叉的不同点在于,除了两边的节点,中间件还有一个节点。这个节点是介于2、4之间的值。 |  |
| 4 | 当随着插入数据,会出现临时的一个节点中,有三个元素。这时会被调整成一个二叉树。 | 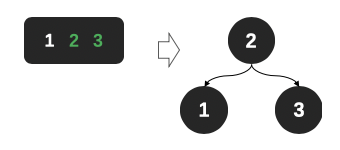 |
综上我们可以总结出,2-3树的一些性质;
- 2-3树所有子叶节点都在同一层
- 1个节点可以有1到2个数据,如果有三个需要调整树结构
- 1个节点1个数据时,则有两个子节点
- 1个节点2个数据时,则有三个子节点,且中间子节点是介于两个节点间的值
# 2. 数据插入
接下来我们就模拟在二叉搜索树中退化成链表的数据,插入到2-3树的变化过程,数据包括;1、2、3、4、5、6、7,插入过程图如下;

以上,就是整个数据在插入过程中,2-3树的演化过程,接下来我们具体讲解每一步的变化;
- α,向节点1插入数据2,此时为了保持平衡,不会新产生分支,只会在一个节点中存放两个节点。
- β,继续插入数据3,此时这个节点有三数据,1、2、3,是一个临时区域。
- γ,把三个数据的节点,中间节点拉起来,调整成树形结构。
- δ,继续插入数据4,为了保持树平衡,会插在节点3的右侧。
- ε,继续插入数据5,插入后
3、4、5共用1个节点,当一个节点上有三个数据时候,则需要进行调整。 - ζ,中间节点4向上⏫调整,调整后,1节点在左、3节点在中间、5节点在右。
- η ,继续插入数据6,在保持树平衡的情况下,与节点5公用。
- θ ,继续插入数据7,插入后,节点7会与当前的节点
5 6共用。此时是一个临时存放,需要调整。初步调整后,抽出6节点,向上存放,变为2 4 6共用一个节点,这是一个临时状态,还需要继续调整。 - ι,因为根节点有三个数据
2、4、6,则继续需要把中间节点上移,1、3和5、7则分别成二叉落到节点2、节点6上。
🇬🇷希腊字母:α(阿尔法)、 β(贝塔)、γ(伽马)、δ(德尔塔)、ε(伊普西隆)、ζ(截塔)、η(艾塔)、θ(西塔)、ι(约塔)
# 3. 数据删除
有了上面数据插入的学习,在看数据删除其实就是一个逆向的过程,在删除的主要包括这样两种情况;
- 删除了3-节点,也就是包含两个数据元素的节点,直接删除即可,不会破坏树平衡。
- 删除了2-节点,此时会破坏树平衡,需要将树高缩短或者元素合并,恢复树平衡。
承接上面👆的例子,我们把数据再从7、6、5、4、3、2、1顺序删除,观察2-3树的结构变化,如下;
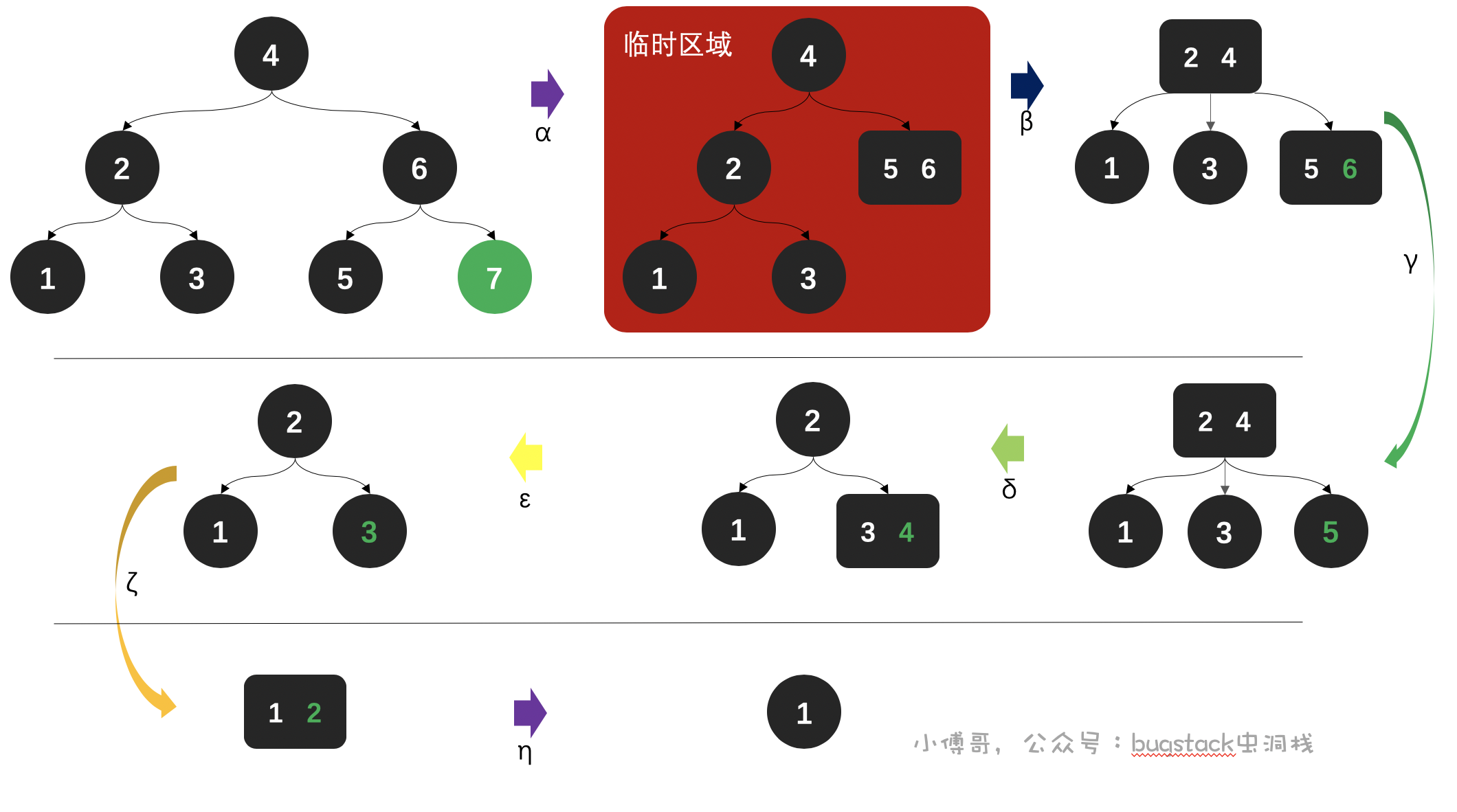
- α,删除节点7,因为节点7只有一个数据元素,删除节点
5、6合并,但此时破坏了2-3树的平衡性,需要缩短树高进行调整。 - β,因为删除节点后,整个树结构不平衡,所以需要缩短树高,调整元素。节点
2、4合并,节点1、3分别插入左侧和中间。 - γ,删除节点6,这个节点是3-节点(可以分出3个叉的意思),删除后不会破坏树平衡,保持不变。
- δ,删除节点5,此时会破坏树平衡,需要把跟节点4下放,与3合并。
- ε,删除节点4,这个节点依旧是3-节点,所以不需要改变树结构。
- ζ,删除节点3,此时只有1、2节点,需要合并。
- η ,删除节点2,此时节点依旧是3-节点,所以不需要改变树结构。
再看一个稍微复杂点2-3树删除:
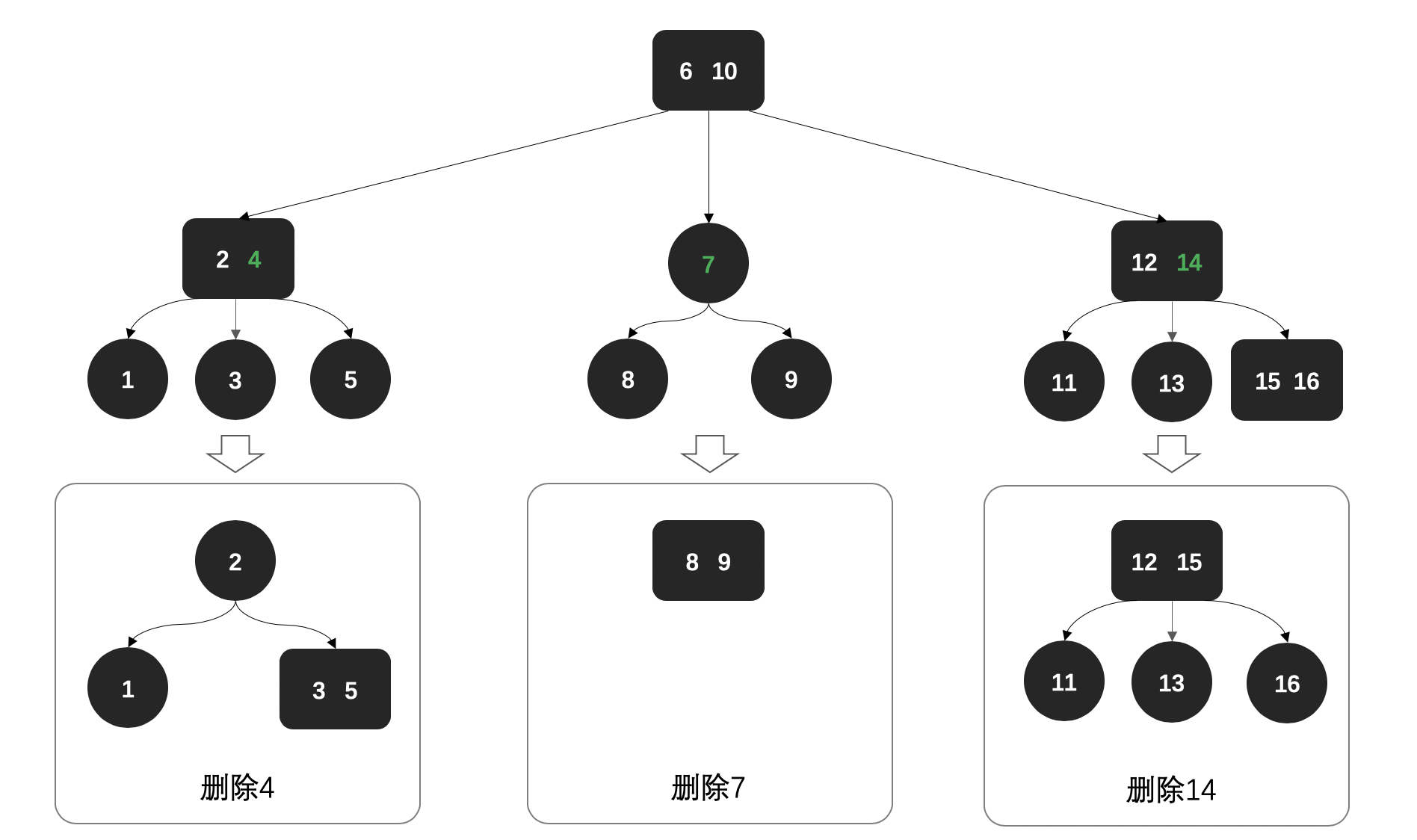
上面👆这张图,就一个稍微复杂点的2-3平衡树,树的删除过程主要包括;
- 删除4,其实需要将节点
3、5合并,指向节点2,保持树平衡。 - 删除7,节点
8、9合并。 - 删除14,节点
15上移,恢复成3-叉树。
🤔如果有时候不好理解删除,可以试想下,这个要删除的节点,在插入的时候是一个什么效果。
# 4. 数据索引
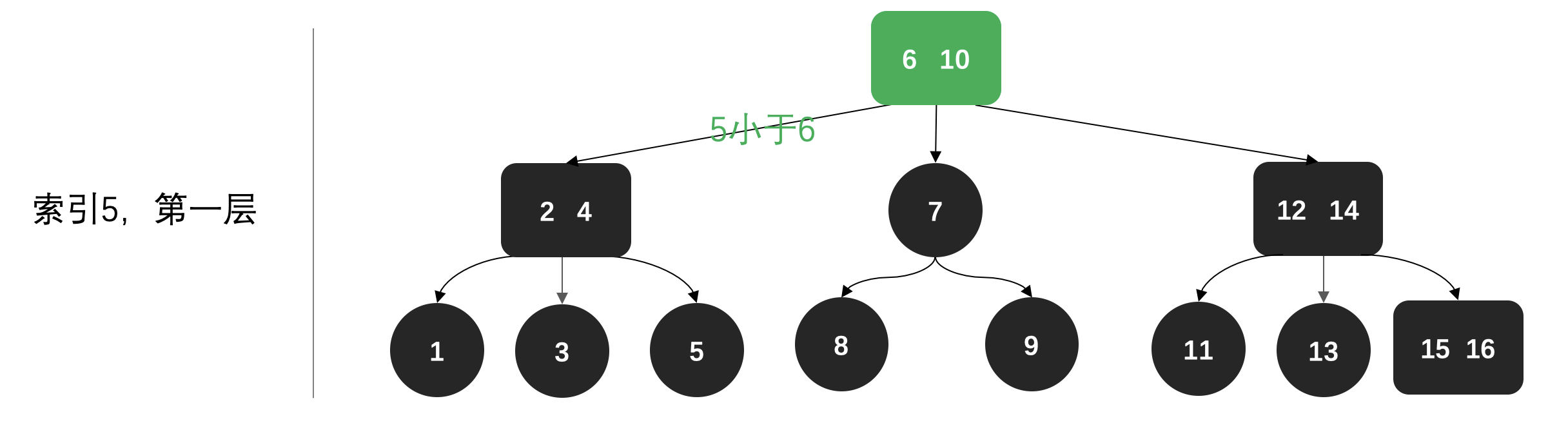
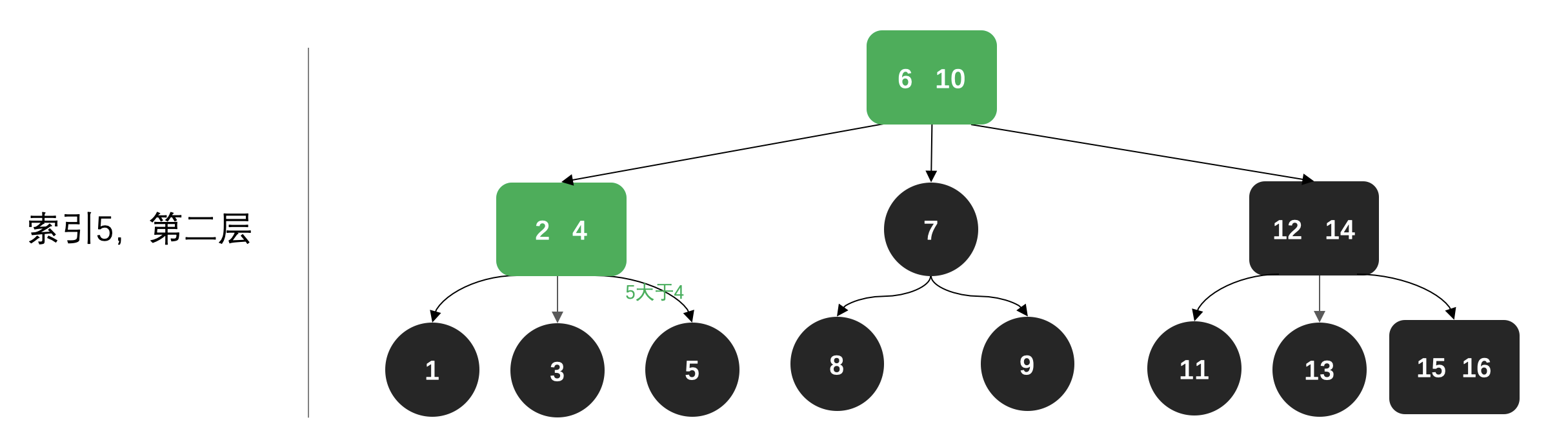
相比于插入和删除,索引的过程还是比较简单的,不需要调整数据结果。基本原则就是;
- 小于当前节点值,左侧寻找
- 大于当前节点值,右侧寻找
- 一直到找到索引值,停止。
🔍第一层寻找:
🔍第二层寻找:
🔍第三次寻找:
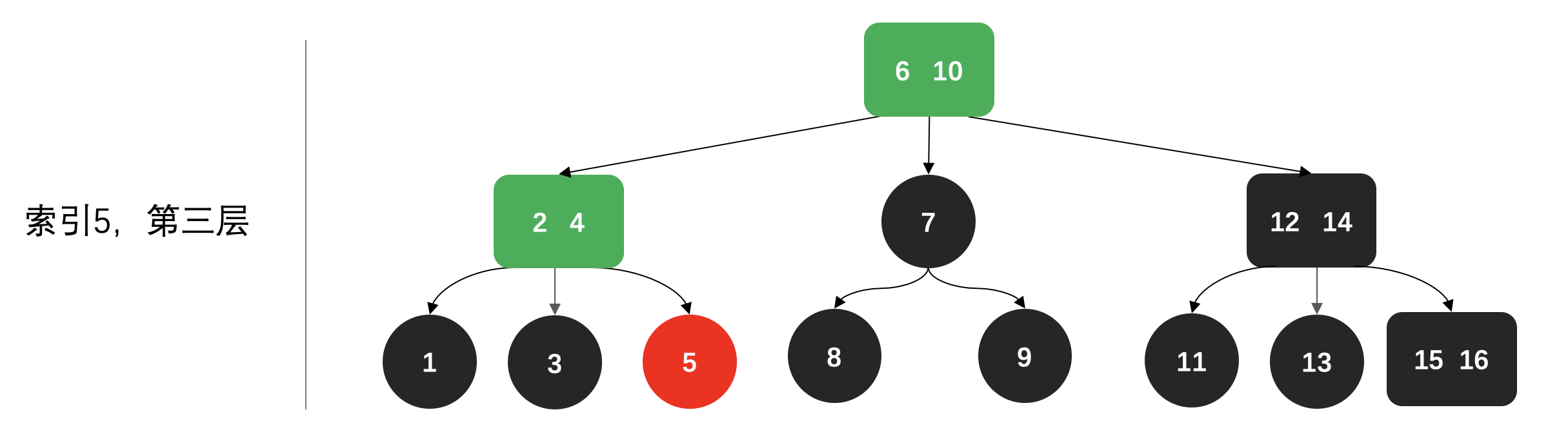
# 五、总结
- 综上讲解了2-3树🌲的核心内容,通过本章节的学习,可以了解2-3树是一种怎样的数据结构、如何插入数据、删除数据以及数据的索引,同时要知道这是一种平衡树的结构,包括2-叉和3-叉节点以及数结构随着数据的添加删除调整。
- 2-3树是红黑树的演变前身,通过这一章节的学习就很容易学习红黑树的相关知识,在红黑树中添加数据进行的渲染、旋转等来保持树平衡。红黑树接近平衡
- 数据结构方面的知识学习起来,可能会比较🤯烧脑,因为需要思考出那种模型结构和变化的过程,所以会感觉困难。但这个烧脑的过程也是对学习非常有帮助的,可以迅速建设知识凸起,当突破不理解到理解,可以有非常多的收获。

京公网安备 11030102010881号
| GPL Licensed | Copyright © 2019 小傅哥,All rights reserved.